Accelerated Infrastructure
for Agentic AI
Build AI faster, smarter, and stronger on a storage system purpose-built for accelerated compute. Whether you are just starting to scale or pushing the limits of real-time reasoning, NeuralMesh™ delivers the speed, flexibility, and efficiency to transform your data infrastructure into an AI advantage.
The world’s leading AI innovators and research teams build on NeuralMesh.












Fast AI. Memory That Scales. Sweet Economics. See How.
AI Moves Fast. So Do Teams Building With WEKA.








“Best in class performance at lower cost for our AI model training and inference clusters.”

Explore Our Latest News and Releases

Build your AI Factory with NeuralMesh
From training to inference, NeuralMesh helps you move data, sustain performance, and deliver persistent value.
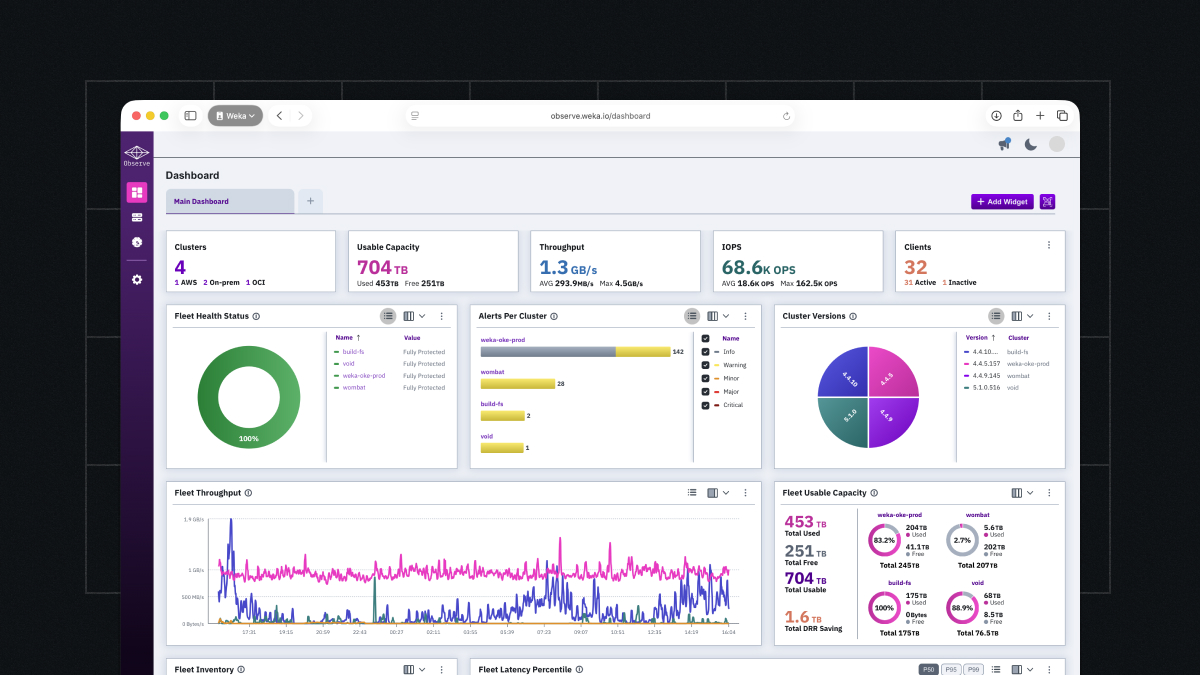
Next Level Visibility and Control for Your WEKA Environment
Learn how WEKA customers get increased visiblity into every workload with NeuralMesh Observe.
Scale AI Innovation Faster With NeuralMesh
Get an inside look at the NeuralMesh ecosystem and learn how leading AI teams are eliminating latency, maximizing GPU utilization, and cutting infrastructure costs.